
一个基于SpringAI+Ollama+RAG的企业知识管理平台
项目背景
企业知识管理一直是个痛点:文档分散、检索效率低、知识孤岛现象严重。传统的全文检索虽然能找到关键词,但缺乏语义理解能力。
这个项目基于 RAG(检索增强生成) 架构,结合大语言模型和向量数据库,实现了:
- 语义级别的知识检索
- 基于上下文的智能问答
- 多轮对话的上下文理解
核心目标是让知识真正”可对话”,而不只是”可检索”,我觉得这个项目是非常有业务价值的。
应用场景
企业内部知识库
- 技术文档检索:API 文档、架构设计、最佳实践
- 流程规范查询:开发规范、code review checklist
- 历史经验沉淀:事故复盘、项目总结
客户支持系统
- 产品文档问答:用户手册、FAQ、troubleshooting
- 技术支持辅助:快速定位问题和解决方案
- 自助服务平台:减少人工客服压力
个人知识库
- 个人知识管理:笔记、文章、书籍摘录
- 论文库检索
核心功能
1. 文档处理与向量化
支持 PDF、Word、Excel、Markdown 等格式,处理流程:
- 使用 Apache Tika 提取文档内容
- 按语义边界分片(默认 500 tokens)
- 通过 Embedding 模型(nomic-embed-text)转换为向量
- 存储到 PGVector 向量数据库
关键是分片策略:既要保证语义完整性,又要控制单片大小以适配模型上下文窗口。
2. RAG 问答引擎
基于检索增强生成(RAG)的问答流程:
- 问题向量化:用户问题通过 Embedding 模型转为向量
- 相似度检索:在 PGVector 中进行余弦相似度搜索
- 上下文构建:取 Top-K 个最相关的文档片段
- LLM 生成:将检索结果作为上下文,使用 qwen2.5 生成回答
支持 Server-Sent Events (SSE) 流式响应,采用 NDJSON 格式增量返回生成内容,提升用户体验。
3. 多轮对话上下文管理
实现了完整的会话管理机制:
- 对话持久化:每个会话(Conversation)包含多条消息(Message)
- 上下文窗口:限制为最近 10 条消息,避免 token 超限
- 历史注入:检索时同时考虑对话历史,提升语义连贯性
这样可以支持连续追问、代词消解等更自然的交互方式。
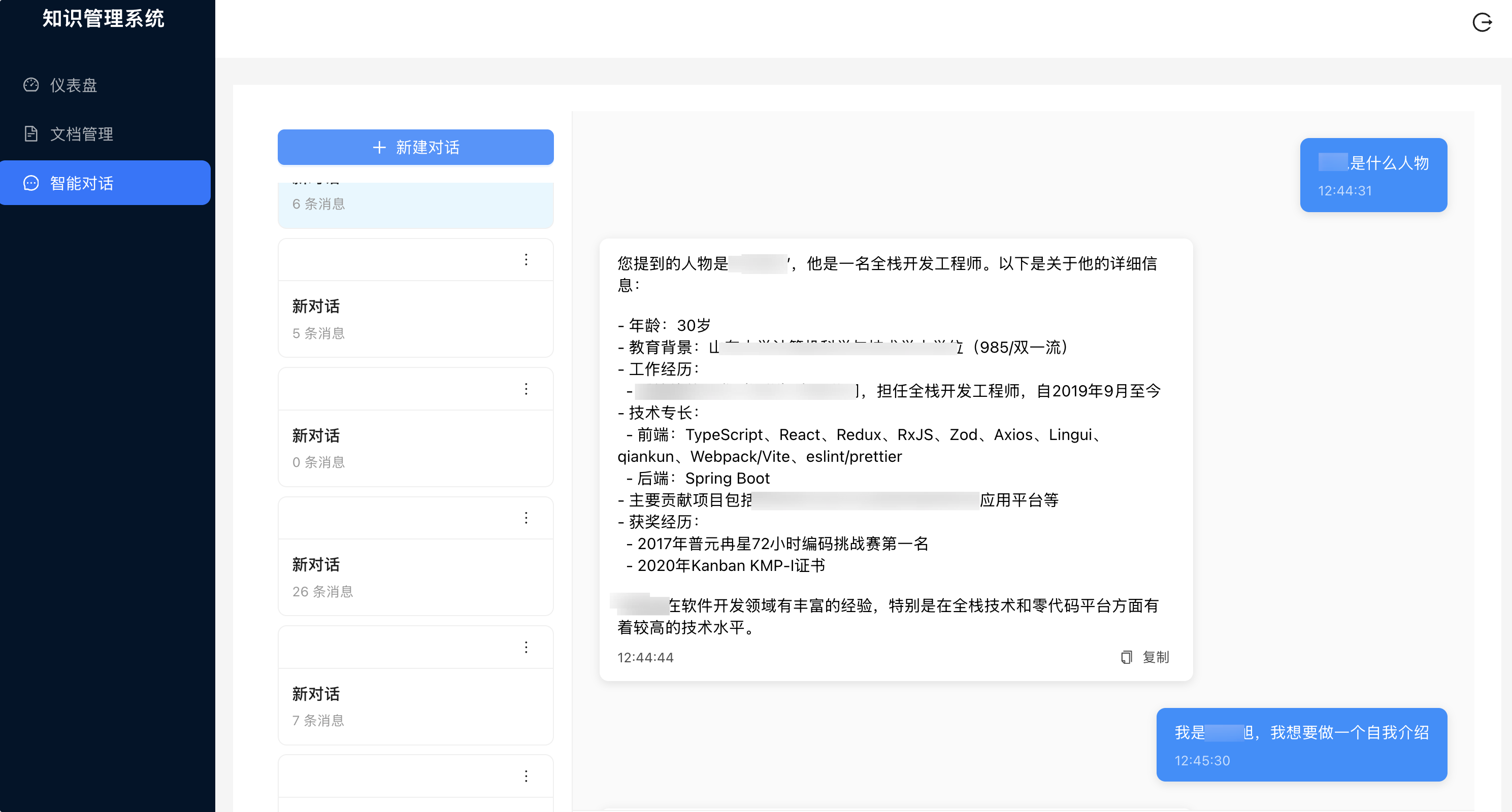
核心功能-智能对话演示:
技术架构
后端技术栈
- Spring Boot 3.3.5 + Spring AI:AI 能力集成框架,简化了与 LLM 的交互
- PostgreSQL 16 + PGVector:关系型数据库 + 向量扩展,统一管理结构化和向量化数据
- Minio:文档对象存储
- Ollama:本地部署的 LLM 推理引擎,支持私有化部署,目前使用的是Qwen系列模型,跟根据私有部署方案灵活切换
- Apache Tika:多格式文档解析库
- Spring Security + JWT:认证授权体系
前端技术栈
- React 18 + TypeScript:类型安全的组件化开发
- Vite:基于 ESM 的快速构建工具
- Ant Design:企业级 UI 组件库
- Axios:HTTP 客户端,支持流式响应处理
RAG 架构设计
RAG(Retrieval-Augmented Generation)是解决大模型”幻觉”问题的有效方案:
公域 LLM 的局限:
- 只能回答公域领域的问题,提供通用答案,无法有效对垂直领域或者是企业私域提供针对性的解决方案
- 容易产生不准确或虚构的内容(幻觉现象)
RAG 的优势:
- 将外部知识库作为动态上下文注入
- 回答有据可查,可追溯到源文档
- 支持领域知识定制,无需重新训练模型
实现细节:
1 | 用户问题 → Embedding → 向量检索(Top-K) → 上下文构建 → LLM生成 → 流式返回 |
技术亮点
1. 流式响应(Server-Sent Events)
采用 NDJSON 格式实现增量传输:
1 | {"type":"start","conversationId":1,"messageId":10} |
前端通过 EventSource 或 fetch 流式处理,逐字渲染,TTFB(首字节时间)显著降低。
2. 会话持久化
- 每个对话独立存储,包含完整的消息历史
- 支持对话重命名、删除、归档
3. 语义检索 vs 全文检索
全文检索(Elasticsearch):
- 基于 BM25 等算法,依赖词频统计
- “性能优化” 和 “提升速度” 无法匹配
向量检索(PGVector):
- 基于语义相似度(余弦距离)
- 理解同义表达、上下文语义
- 支持跨语言检索(取决于 Embedding 模型)
4. 多租户数据隔离
- 基于
tenant_id的行级数据隔离 TenantContext管理当前租户上下文- JPA 自动注入租户过滤条件
未来规划
这个项目还在持续优化中,计划添加:
- ✅ 已完成:文档管理、向量解析、流式对话、对话管理、多轮上下文
- 🚧 正在做:集成 MinIO,目前还只是上传到一个临时目录而已
- 📋 规划中:
- 文档分组管理
- 答案可以追溯到源文档,提供依据
- Markdown 渲染 + 代码高亮
- 在线编辑
- 对话导出功能(保存成 PDF)
- 使用ES实现全文检索
- 使用图数据库实现知识图谱可视化(看看文档之间的关联)
- 多租户和权限管理
- 移动端适配
- 多语言支持
项目已开源,欢迎交流与贡献。
项目地址: https://github.com/penghs520/knowledge-management
如果对 RAG、向量数据库、大模型私有部署、 Spring AI 感兴趣,欢迎关注和讨论。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 我的代码世界!