1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
| package cn.zeros;
import java.util.*;
import java.util.stream.Collectors;
public class JavaStreamDebug {
public static void main(String[] args) {
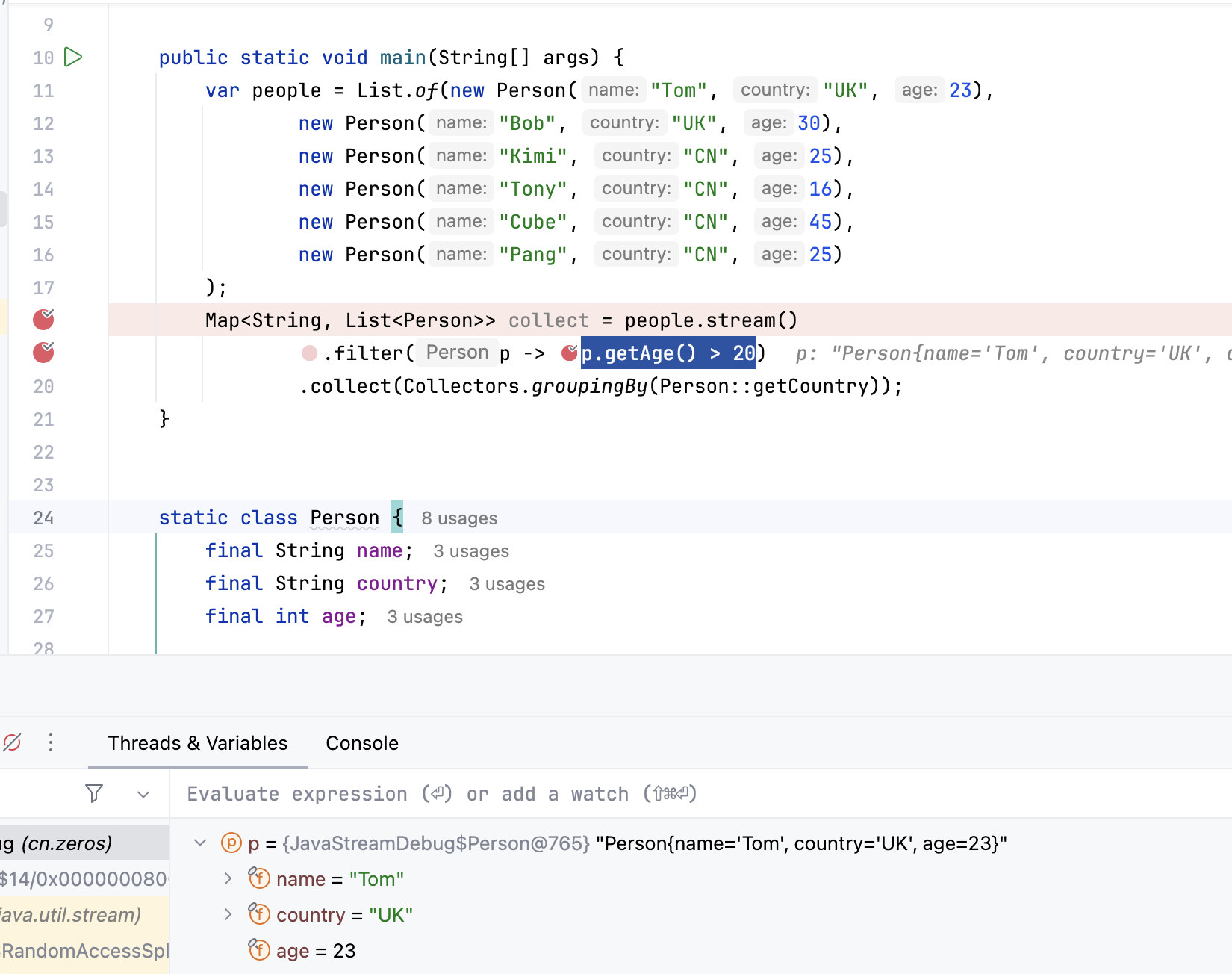
var people = List.of(
new Person("Tom", "UK", 23, "Engineer"),
new Person("Bob", "UK", 30, "Manager"),
new Person("Kimi", "CN", 25, "Developer"),
new Person("Tony", "CN", 16, "Student"),
new Person("Cube", "CN", 45, "Director"),
new Person("Pang", "CN", 25, "Developer"),
new Person("Alice", "US", 28, "Designer"),
new Person("John", "US", 35, "Manager"),
new Person("Emma", "UK", 22, "Intern"),
new Person("David", "US", 40, "Architect")
);
System.out.println("\n=== 1. 按国家分组,计算每个国家的平均年龄和人数 ===");
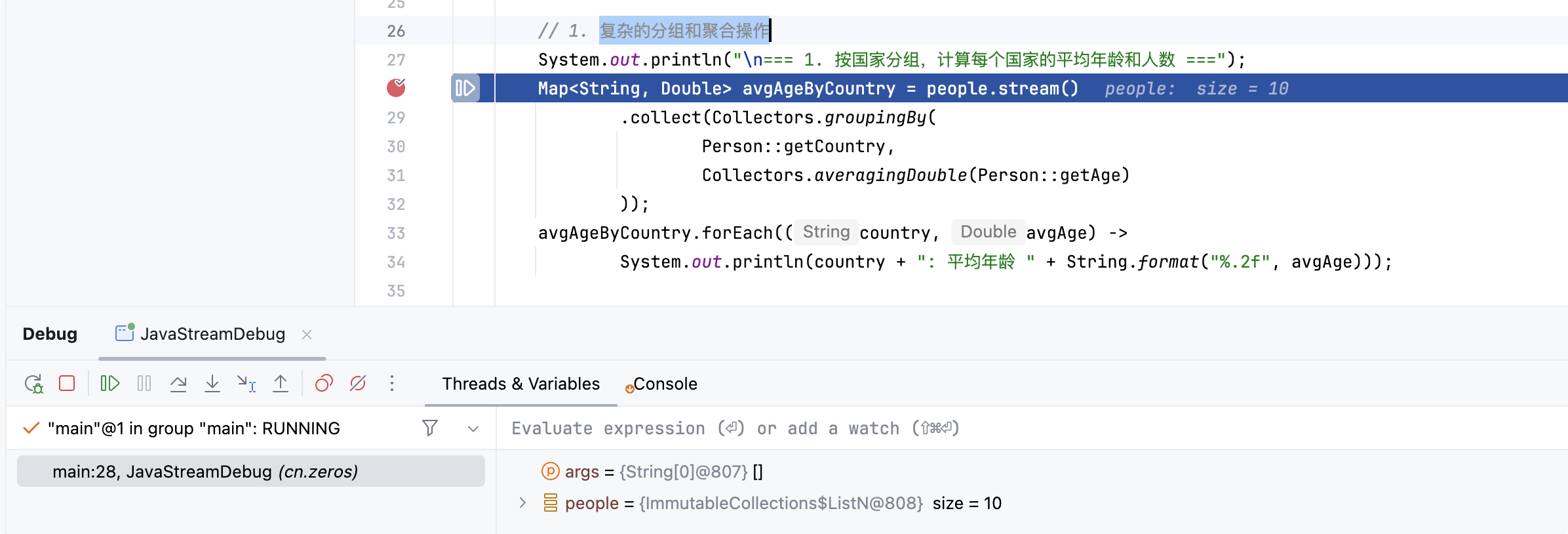
Map<String, Double> avgAgeByCountry = people.stream()
.collect(Collectors.groupingBy(
Person::getCountry,
Collectors.averagingDouble(Person::getAge)
));
avgAgeByCountry.forEach((country, avgAge) ->
System.out.println(country + ": 平均年龄 " + String.format("%.2f", avgAge)));
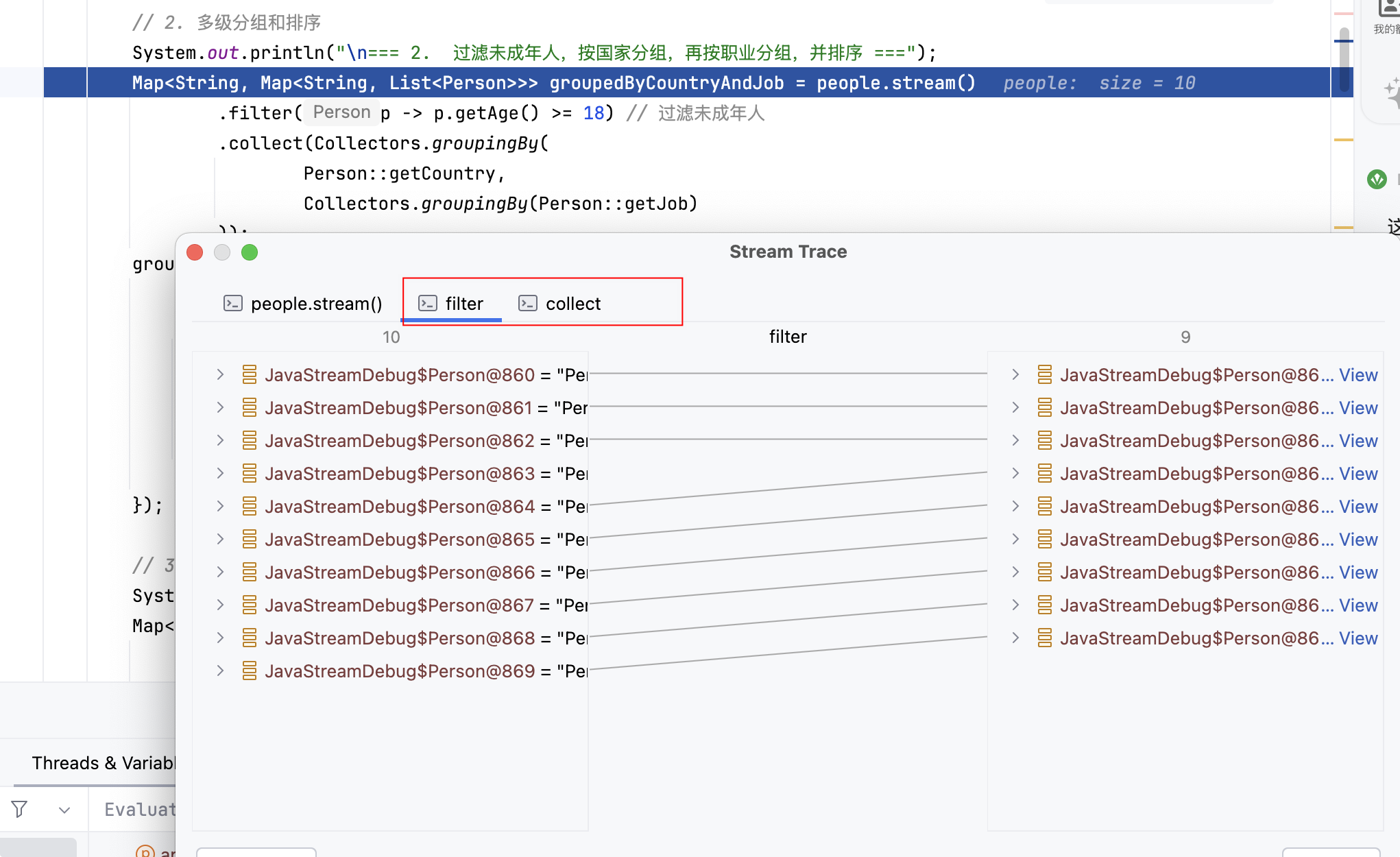
System.out.println("\n=== 2. 按国家分组,再按职业分组,并排序 ===");
Map<String, Map<String, List<Person>>> groupedByCountryAndJob = people.stream()
.filter(p -> p.getAge() >= 18)
.collect(Collectors.groupingBy(
Person::getCountry,
Collectors.groupingBy(Person::getJob)
));
groupedByCountryAndJob.forEach((country, jobMap) -> {
System.out.println("\n" + country + ":");
jobMap.forEach((job, personList) -> {
System.out.println(" " + job + ": " + personList.size() + "人");
personList.stream()
.sorted(Comparator.comparing(Person::getAge).reversed())
.forEach(p -> System.out.println(" " + p));
});
});
System.out.println("\n=== 3. 找出每个国家最年长的人 ===");
Map<String, Optional<Person>> oldestByCountry = people.stream()
.collect(Collectors.groupingBy(
Person::getCountry,
Collectors.maxBy(Comparator.comparing(Person::getAge))
));
oldestByCountry.forEach((country, oldest) ->
oldest.ifPresent(p -> System.out.println(country + "最年长: " + p)));
System.out.println("\n=== 4. 生成所有可能的姓名组合(用于测试flatMap) ===");
List<String> firstNames = List.of("Alex", "Chris", "Sam");
List<String> lastNames = List.of("Smith", "Johnson", "Brown");
List<String> fullNames = firstNames.stream()
.flatMap(firstName ->
lastNames.stream()
.map(lastName -> firstName + " " + lastName)
)
.collect(Collectors.toList());
fullNames.forEach(System.out::println);
System.out.println("\n=== 5. 年龄统计信息 ===");
IntSummaryStatistics ageStats = people.stream()
.mapToInt(Person::getAge)
.summaryStatistics();
System.out.println("年龄统计: " + ageStats);
System.out.println("\n=== 6. 计算所有成年人年龄的加权平均(按国家人口权重) ===");
Map<String, Long> countryCounts = people.stream()
.filter(p -> p.getAge() >= 18)
.collect(Collectors.groupingBy(Person::getCountry, Collectors.counting()));
double weightedAvg = people.stream()
.filter(p -> p.getAge() >= 18)
.mapToDouble(p -> p.getAge() * countryCounts.get(p.getCountry()))
.sum() / countryCounts.values().stream().mapToLong(Long::longValue).sum();
System.out.println("加权平均年龄: " + String.format("%.2f", weightedAvg));
System.out.println("\n=== 7. 使用peek调试流处理过程 ===");
List<String> debugResult = people.stream()
.peek(p -> System.out.println("处理: " + p))
.filter(p -> p.getAge() > 25)
.peek(p -> System.out.println("年龄>25: " + p))
.map(Person::getName)
.peek(name -> System.out.println("提取姓名: " + name))
.sorted()
.peek(name -> System.out.println("排序后: " + name))
.collect(Collectors.toList());
System.out.println("最终结果: " + debugResult);
System.out.println("\n=== 8. 按国家收集人员信息(包含统计) ===");
Map<String, Map<String, Object>> countryStats = people.stream()
.collect(Collectors.groupingBy(
Person::getCountry,
Collectors.collectingAndThen(
Collectors.toList(),
list -> {
Map<String, Object> stats = new HashMap<>();
stats.put("count", list.size());
stats.put("avgAge", list.stream().mapToInt(Person::getAge).average().orElse(0));
stats.put("maxAge", list.stream().mapToInt(Person::getAge).max().orElse(0));
stats.put("minAge", list.stream().mapToInt(Person::getAge).min().orElse(0));
stats.put("names", list.stream().map(Person::getName).collect(Collectors.toList()));
return stats;
}
)
));
countryStats.forEach((country, stats) -> {
System.out.println("\n" + country + ":");
stats.forEach((key, value) -> System.out.println(" " + key + ": " + value));
});
System.out.println("\n=== 9. 并行流处理(模拟耗时操作) ===");
long startTime = System.currentTimeMillis();
List<String> parallelResult = people.parallelStream()
.filter(p -> p.getAge() >= 20)
.map(p -> {
try {
Thread.sleep(10);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
return p.getName().toUpperCase() + " (" + p.getCountry() + ")";
})
.collect(Collectors.toList());
long endTime = System.currentTimeMillis();
System.out.println("并行处理结果: " + parallelResult);
System.out.println("并行处理耗时: " + (endTime - startTime) + "ms");
System.out.println("\n=== 10. 自定义收集器:收集年龄范围信息 ===");
AgeRangeInfo ageRangeInfo = people.stream()
.collect(new AgeRangeCollector());
System.out.println("年龄范围信息: " + ageRangeInfo);
}
static class AgeRangeCollector implements java.util.stream.Collector<Person, AgeRangeInfo, AgeRangeInfo> {
@Override
public java.util.function.Supplier<AgeRangeInfo> supplier() {
return AgeRangeInfo::new;
}
@Override
public java.util.function.BiConsumer<AgeRangeInfo, Person> accumulator() {
return (info, person) -> info.addPerson(person);
}
@Override
public java.util.function.BinaryOperator<AgeRangeInfo> combiner() {
return (info1, info2) -> {
info1.merge(info2);
return info1;
};
}
@Override
public java.util.function.Function<AgeRangeInfo, AgeRangeInfo> finisher() {
return info -> info;
}
@Override
public Set<Characteristics> characteristics() {
return Set.of(Characteristics.UNORDERED);
}
}
static class AgeRangeInfo {
private int minAge = Integer.MAX_VALUE;
private int maxAge = Integer.MIN_VALUE;
private int totalAge = 0;
private int count = 0;
public void addPerson(Person person) {
int age = person.getAge();
minAge = Math.min(minAge, age);
maxAge = Math.max(maxAge, age);
totalAge += age;
count++;
}
public void merge(AgeRangeInfo other) {
minAge = Math.min(minAge, other.minAge);
maxAge = Math.max(maxAge, other.maxAge);
totalAge += other.totalAge;
count += other.count;
}
public double getAverageAge() {
return count > 0 ? (double) totalAge / count : 0;
}
@Override
public String toString() {
return String.format("年龄范围: %d-%d, 平均年龄: %.2f, 总人数: %d",
minAge, maxAge, getAverageAge(), count);
}
}
@Getter
@ToString
static class Person {
final String name;
final String country;
final int age;
final String job;
Person(String name, String country, int age, String job) {
this.name = name;
this.country = country;
this.age = age;
this.job = job;
}
}
}
|